

Thư viện được xem như là một nguồn tài nguyên quan trọng giúp chúng ta trong việc nghiên cứu, xây dựng, và phát triển những dự án trong tương lai. Khi xét đến ngôn ngữ lập trình Python, Pandas là thư viện khá gần gũi.
Do đó, bài viết này sẽ hướng dẫn bạn cách thức tiếp cận, cơ chế vận hành và làm sao để sử dụng thư viện này sao cho hiệu quả.

{index}
Thư viện Pandas trong Python
Pandas được dân lập trình ví như một thư viện tuyệt vời, hoặc như nguồn tài nguyên nhằm hỗ trợ việc phân tích cũng như xử lý dữ liệu. Không những thế, những dạng xử lý, lọc hay tổng hợp dữ liệu hiện nay đều rất cần sự trợ giúp từ thư viện này.
Mặt khác, thư viện được hình thành từ ngôn ngữ lập trình Python hay được dùng cho tất cả những tác vụ tổng hợp thông tin cụ thể từ bất kỳ dữ liệu. Khi bàn đến ngành khoa học dữ liệu, thư viện Pandas được đánh giá như một người bạn đắc lực trong quy trình phân tích và giải quyết các vấn đề kèm theo mã nguồn mở dễ tiếp cận và linh hoạt.

Tại sao phải dùng thư viện Pandas trong Python?
Trên thực tế, thư viện Pandas được đánh giá như ngôi nhà phân tầng dữ liệu của nhà phát triển. Khi sử dụng thư viện này, người dùng sẽ có cơ hội tiếp cận đến những dữ liệu thông qua phân tích hay cập nhật chúng.
Những tính năng chính của thư viện Pandas
Như các bạn đã biết, Pandas là thư viện mở được dùng phổ biến trong ngành phân tích dữ liệu. Hơn thế nữa, nó hỗ trợ bạn thao tác trên dữ liệu bảng. Sau đây, chúng tôi xin phép điểm qua những tính năng chính nằm trong thư viện Pandas.
– Giúp bạn ghi/đọc dữ liệu từ những nguồn tài nguyên khác. Nói cách khác, nó hỗ trợ lập trình viên ghi hay đọc dữ liệu từ các nguồn như: CSV, SQL, hay Parquet.
– Làm sạch dữ liệu: thư viện mang đến nhiều công cụ phục vụ cho việc làm sạch như lọc giá trị trùng hay biến đổi dữ liệu.
– Truy vấn dữ liệu: hỗ trợ truy vấn hay lọc dữ liệu từ những điều kiện đặt ra như giá trị, và các biểu thức.
– Gộp và ghép dữ liệu: giúp bạn gộp hay ghép những bảng dữ liệu dựa trên những yêu cầu khác nhau.
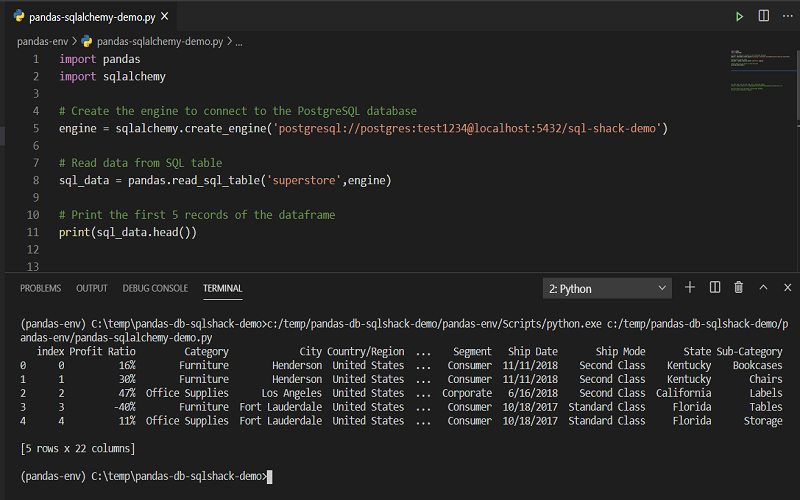
Cách cài đặt thư viện Pandas trong Python
Phần này sẽ giúp bạn hiểu thêm về quá trình cài đặt thư viện Pandas. Trước tiên, chúng ta nên dùng một trình quản lý gói phổ biến như pip. Sau đây, mời các bạn theo dõi quá trình cài đặt Pandas.
1. Người dùng hãy mở command prompt hay terminal
2. Sau đó, gõ lệnh và nhấn nút “Enter” để cài phiên bản mới nhất của pip.
pip install --upgrade pip3. Tiếp đến, các bạn gõ lệnh bên dưới để tiến hành cài đặt.
pip install pandas4. Cuối cùng, chờ đợi quá trình cài đặt diễn ra và hoàn tất.
Lúc này, người dùng hãy nhập lệnh để kiểm tra Pandas đã cài hay chưa nhé.
import pandas as pdNgoài ra, nếu hệ thống không xuất hiện hộp thoại hay thông báo lỗi thì quá trình cài đặt thư viện Pandas trong Python đã thành công.
Những kiểu dữ liệu trong thư viện Pandas
Trong Python, thư viện Pandas sẽ hỗ trợ đa dạng các kiểu dữ liệu nhằm phục vụ việc xử lý dữ liệu trên bảng như:
1. DataFrame: kiểu dữ liệu chính trên Pandas và dùng để tượng trưng một bảng dữ liệu
2. Series: kiểu dữ liệu một chiều
3. Index: dùng để biểu thị cho chỉ mục từ những hàng hay cột trong DataFrame.
4. MultiIndex: dùng để biểu thị cho chỉ mục đa cấp.
5. Timedelta: dùng để chỉ khoảng thời gian
6. Sparse: phục vụ cho việc lưu dữ liệu thưa với những giá trị thiếu hiển thị qua NaN.
7. Categorical: được dùng để tượng trưng cho những biến phân loại.
8. Interval: hỗ trợ cho việc thể hiện những khoảng giá trị.
9. Period: cũng tương tự như kiểu dữ liệu Interval nhưng nó thể hiện khoảng thời gian.
10. DatetimeIndex: được dùng để biểu thị cho những chỉ mục mang kiểu datetime.
Tóm lại, những kiểu dữ liệu trên có thể dùng để tính toán dữ liệu trong bảng.
Cấu trúc dữ liệu trong thư viện Pandas
Pandas sẽ hỗ trợ ba cấu trúc dữ liệu và mang lại nhiều lợi ích và sự hiệu quả cao cho người lập trình. Ba cấu trúc gồm: Series, DataFrame, Panel. Tuy nhiên, Panel không được phổ biến và dần bị thay thế nên chúng tôi chỉ điểm qua hai cấu trúc dữ liệu chính là Series và DataFrame.
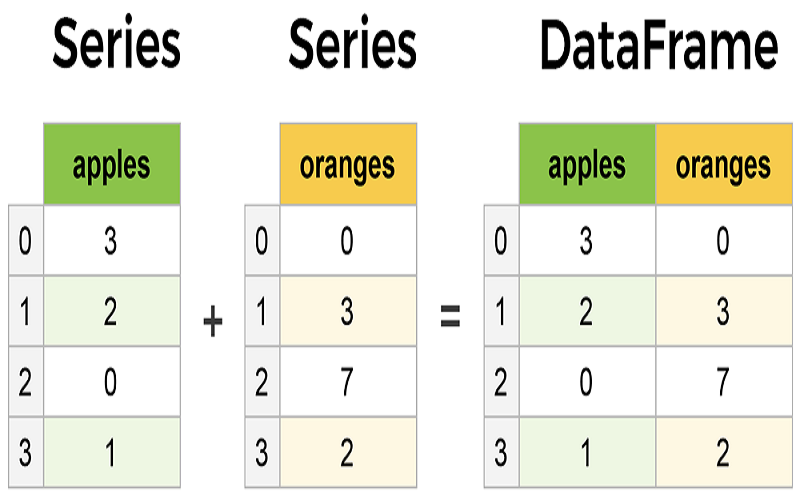
1. Series
Series được hiểu là một kiểu dữ liệu mảng một chiều. Nó được dùng để biểu thị một hàng hay cột trong DataFrame. Thông thường, mỗi phần tử đều mang một index (chỉ mục) để hỗ trợ cho quá trình truy xuất hay phân tích dữ liệu dễ dàng và tiện hơn.
Để giúp các bạn hiểu thêm về nó, chúng tôi xin đưa ra ví dụ sau.
Ví dụ:
import pandas as pd
# Khởi tạo một Series gồm các số nguyên từ 0 đến 4
s = pd.Series([0, 1, 2, 3, 4])
# In ra Series và chỉ mục tương ứng của mỗi phần tử
print(s)
print(s.index)
# Truy xuất phần tử thứ hai của Series
print(s[1])
# Truy xuất các phần tử có chỉ mục từ 1 đến 3 của Series
print(s[1:4])
# Tạo một Series mới với chỉ mục là các chữ cái
s2 = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
# In ra Series và chỉ mục tương ứng của mỗi phần tử
print(s2)
print(s2.index)
# Truy xuất phần tử có chỉ mục là 'b' của Series
print(s2['b'])
# Truy xuất các phần tử có chỉ mục từ 'b' đến 'd' của Series
print(s2['b':'d'])Sau đó, hãy chạy đoạn mã trên để hiển thị kết quả.
Kết quả:
0 0
1 1
2 2
3 3
4 4
dtype: int64
RangeIndex(start=0, stop=5, step=1)
1
1 1
2 2
3 3
dtype: int64
a 10
b 20
c 30
d 40
e 50
dtype: int64
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
20
b 20
c 30
d 40
dtype: int64Từ ví dụ trên cho thấy khi tạo hai Series khác nhau, một tương ứng với chỉ mục là những số nguyên và một là chỉ mục liên quan đến những chữ cái. Người dùng nên truy xuất hay in những phần tử kèm theo những chỉ mục liên quan đến chúng.
Từ đó, việc dùng những phép truy xuất để lọc ra những phần tử riêng biệt từ cấu trúc dữ liệu Series.
2. DataFrame
DataFrame được biết đến như một kiểu dữ liệu hai chiều nằm trong thư viện Pandas. Có thể hiểu nó như một bảng dữ liệu của SQL hay một bảng tính trong Excel. Nó chứa những hàng hay cột và mỗi cột sẽ hiển thị một Series.
Ví dụ:
import pandas as pd
# Khởi tạo một DataFrame từ một dictionary chứa các Series
data = {'name': pd.Series(['Alice', 'Bob', 'Charlie']),
'age': pd.Series([25, 30, 35]),
'city': pd.Series(['Hanoi', 'HCM', 'Da Nang'])}
df = pd.DataFrame(data)
# In ra DataFrame
print(df)
# Truy xuất các hàng và cột của DataFrame
print(df['name'])
print(df.age)
print(df.loc[1])
print(df.iloc[0:2, 1:3])Sau đó, các bạn chạy đoạn mã trên để biết kết quả.
Kết quả:
name age city
0 Alice 25 Hanoi
1 Bob 30 HCM
2 Charlie 35 Da Nang
0 Alice
1 Bob
2 Charlie
Name: name, dtype: object
0 25
1 30
2 35
Name: age, dtype: int64
name Bob
age 30
city HCM
Name: 1, dtype: object
age city
0 25.0 Hanoi
1 30.0 HCMNhư vậy, ví dụ trên đã giúp người dùng hiểu thêm về DataFrame. Đầu tiên, tạo một DataFrame từ một Dictionary bao gồm những Series. Sau đó, cùng nhau triển khai các phép truy xuất để xuất ra những hàng/cột từ DataFrame.
Từ đó, dùng chỉ mục hay tên liên quan đến chúng. Không những thế, các bạn có thể dùng hai phương thức loc hay iloc để truy xuất những phần tử kèm theo hàng từ DataFrame liên quan đến vị trí hay chỉ mục.
Lời kết
Bài viết đã tổng hợp và nêu ra những thông tin cực kỳ hữu ích liên quan đến thư viện Pandas trong Python. Chúng tôi hy vọng nó sẽ hỗ trợ phần nào cho người dùng trong quá trình tiếp cận và sử dụng thư viện này trong tương lai.